1. ¿Cómo funciona el Data Fabric?
1.3. Suite de Gobierno del Dato
Normalmente el problema con el que nos encontramos es que estos esquemas se entienden mal por parte de usuarios no técnicos, por lo que en el segundo paso lo que hacemos será traducirlos a significado y términos de negocio.
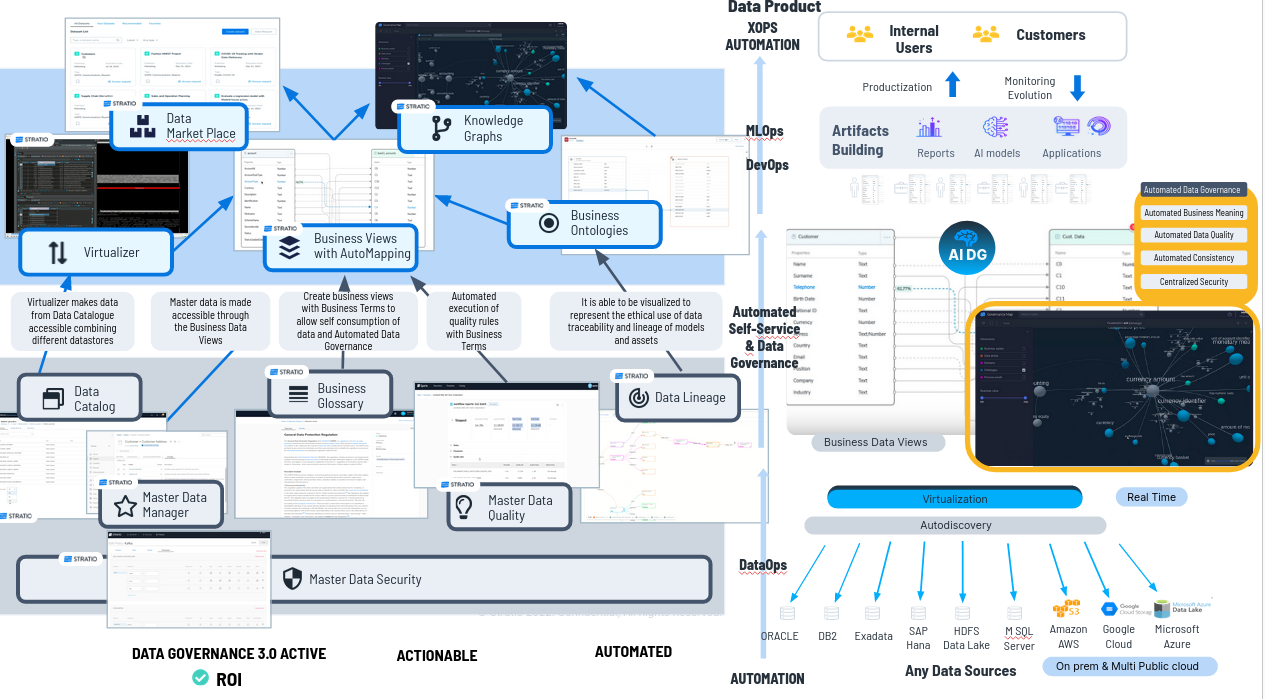
Creamos un
producto que se llama "Data Collections" que sea capaz de crear una vista
de negocio y creamos tantas "Business Views" como queramos, porque no consumen
practicamente recursos.
Estas Business Views contendrán términos de negocio que vienen desde el glosario de negocio (Business Glossary) o palabras que los usuarios de negocio entienden perfectamente,
siendo las que nuestros clientes usan en el día a día.
A continuación ayudamos a mapear semi automáticamente los términos de negocio, las propiedades de la business view, con los datos que están disponibles a través del virtualizador y una vez que los he mapeado, publico la vista de negocioy los usuarios pueden consumir los datos con las vistas de negocio.
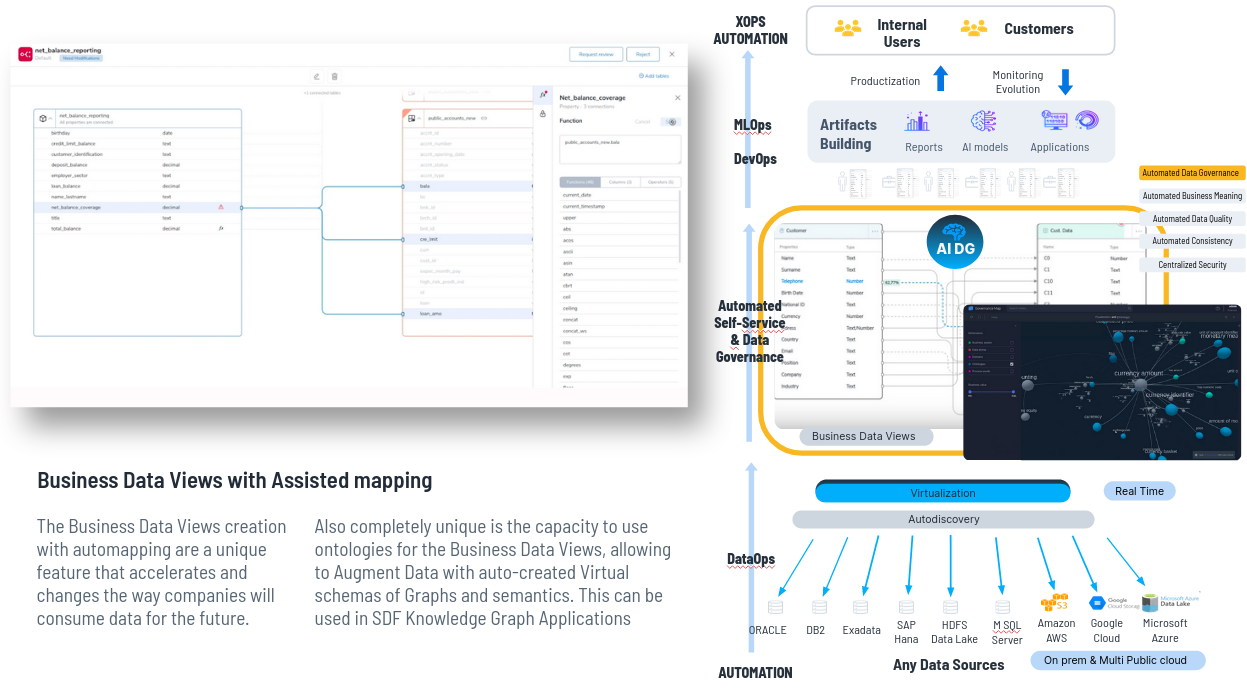
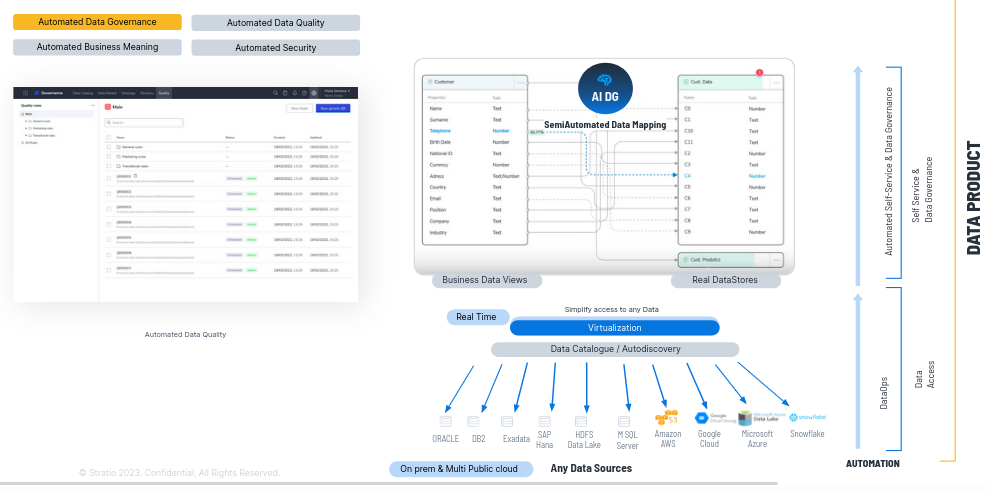
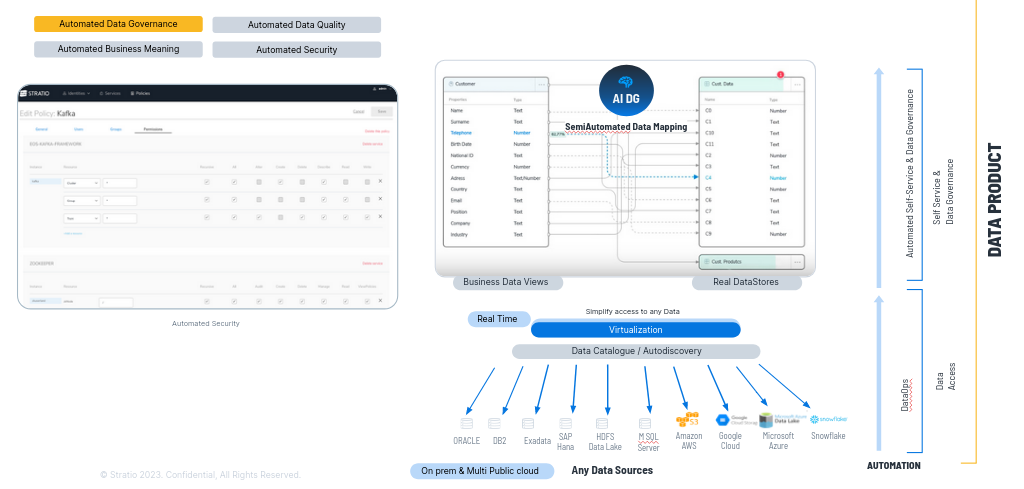
Permitimos el autoconsumo del dato porque lo entienden perfectamente. Además al mapear hacemos gobierno del dato semi-automáticamente.
Ejemplo: Al mapear, en una tabla de un Oracle, una columna se llamaba C4 pero hemos identificado con algoritmia que en realidad es el teléfono, con lo que al mapearlo además de poder acceder a ese dato con teléfono en lugar de con C4 hacemos gobierno del dato automáticamente, automatizamos el gobierno del dato, podemos ejecutar la reglas de calidad de teléfono de C4 porque ahora sabemos lo que es.
___________________________________________________________________________________________________________________________________________________________
¿Qué estamos
haciendo?
Transformamos los datos en CONFIABLES, “trusted”, con calidad y con
seguridad . Así cuando utilizamos estas vistas, además de ontologías
propiamente formadas, somos capaces de aumentar los datos al
hacer el mapeo con esquemas de grafos o esquema semánticos con lo que
todos los casos de uso de clientes los mejoramos.
Permitimos el AUTOCONSUMO DEL DATO porque traducimos los datos técnicos a términos de negocio y TRANSFORMAMOS EL DATO EN CONFIABLE y lo AUMENTAMOS, justo lo que indican Forrester y Gartner que hay que hacer.
Cuando
además en estas vistas se utilizan ontologías somos capaces de crear
esquemas de grafos y semánticos para poder resolver problemas de mejor
manera.
___________________________________________________________________________________________________________________________________________________________
¿Cómo hacemos el movimiento a
Public Cloud?
Con las vistas de negocio nosotros somos capaces no solo
de mapear datos sino de crear nuevos datos. Se pueden utilizar fórmulas
matemáticas o scripts con SQL para combinar los datos que me llegan.
Luego esos datos si a esta business view se les añade un atributo,
por ejemplo: replication_destiny=aws.snowflake/microsofazure.gen2 u otro; y
automáticamente el virtualizador lo mueve donde queramos.
Estamos
haciendo un datalake en la nube con unos solos clicks, y además lo
hacemos desde gobierno del dato. Movemos desde la definición de negocio,
no técnicamente. Defino un KPI desde mi business glossary y con una
formula y se me genera el dato.
¡Tardamos días en lugar de meses o años en mover datos de un data lake a una public cloud!
___________________________________________________________________________________________________________________________________________________________