Documentacion: Stratio Generative AI Data Fabric como Fabrica de Datos
| Sitio: | STRATIO Training & Certification |
| Curso: | Stratio Generative AI Data Fabric Basic Business 14.6 |
| Libro: | Documentacion: Stratio Generative AI Data Fabric como Fabrica de Datos |
| Imprimido por: | Invitado |
| Día: | lunes, 22 de diciembre de 2025, 09:05 |
1. ¿Cómo funciona el Data Fabric?
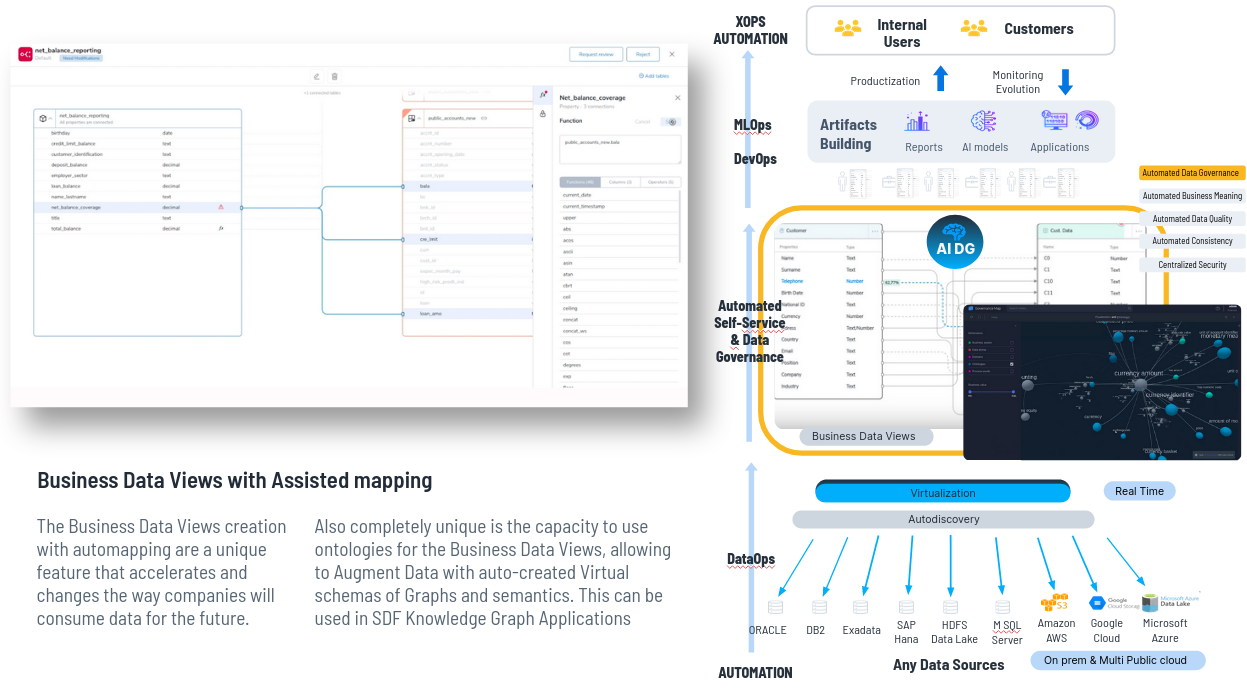
La fabrica de datos
automatiza lo que hemos visto que pasaba en generaciones anteriores, principalmente las tareas tediosas como acceso a los datos.
El Data Fabric lo que hace es que con sus fuentes de autodescubrimiento se conectan a esas bases de datos autodescubre los datos y genera un Catálogo de Datos.
¿Cómo resuelve Stratio estos problemas utilizando Data Fabric?
Cada uno de los casos de uso es un Data Product que pretende que obtengamos valor de los datos. Stratio Augmented Data Fabric cubre todas las capasa de un Data Product.
¿Cómo falicilita el Data Fabric la aplicación de IA Generativa?
El Data fabric es clave como facilitador de Gen AI. Cualquier producto que no facilite el uso de Gen AI para productivizar de forma automática el uso de estos Data Products, no tiene cabida en el mercado actual.
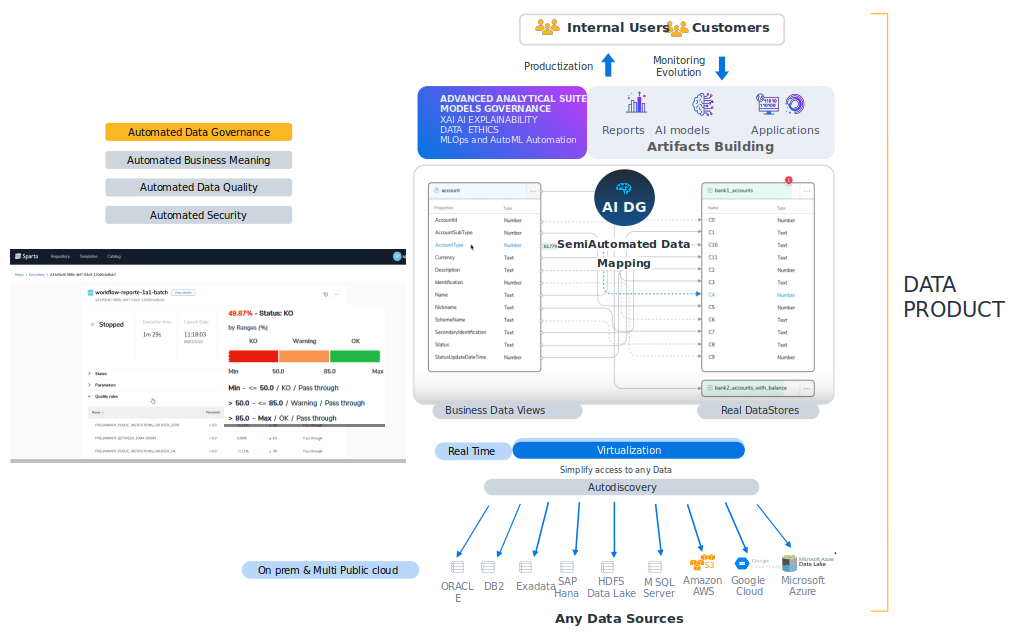
Hay estas partes principales en la plataforma.
Acceso al Dato y Autodescubrimiento
Virtualizador
Suite de Gobierno del Data
- Suite IA Generativa
- Data Product Market Place
- Suite de Analítica avanzada
1.1. Acceso al Dato y Autodescubrimiento
Construimos una serie de productos uno de ellos el DataCatalog en el que somos capaces con agentes de auto-descubrimiento de diferentes sistemas de datos nos conectamos a esas fuentes de datos y automáticamente generamos un catálogo de datos, de forma 100% automática, no se necesita intervención humana.
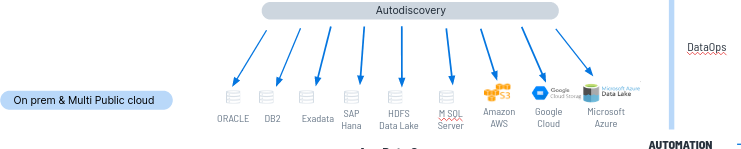
"DataCatalog" es una tendencia muy fuerte. En el camino hacia la madurez del dato, lo primero que necesitan las empresas es saber qué datos tienen.
1.2. Virtualizador
Una vez creado el catálogo de datos, nuestro virtualizador permite acceder a todos esos datos de manera fusionada es decir creamos una capa de datos UNIFICADA y permite el movimiento de datos.
El virtualizador
es el motor de ejecución de acceso a los datos de la compañía, es
decir, a todos los datos que hay en el Data Catalog. Es también el que ejecuta el código que genera el motor de IA
Generativa, para acceder a cualquier dado. Lo genera para SQL,
reporting, dashboards, ejecuta código de modelos (Python, Spark, etc)
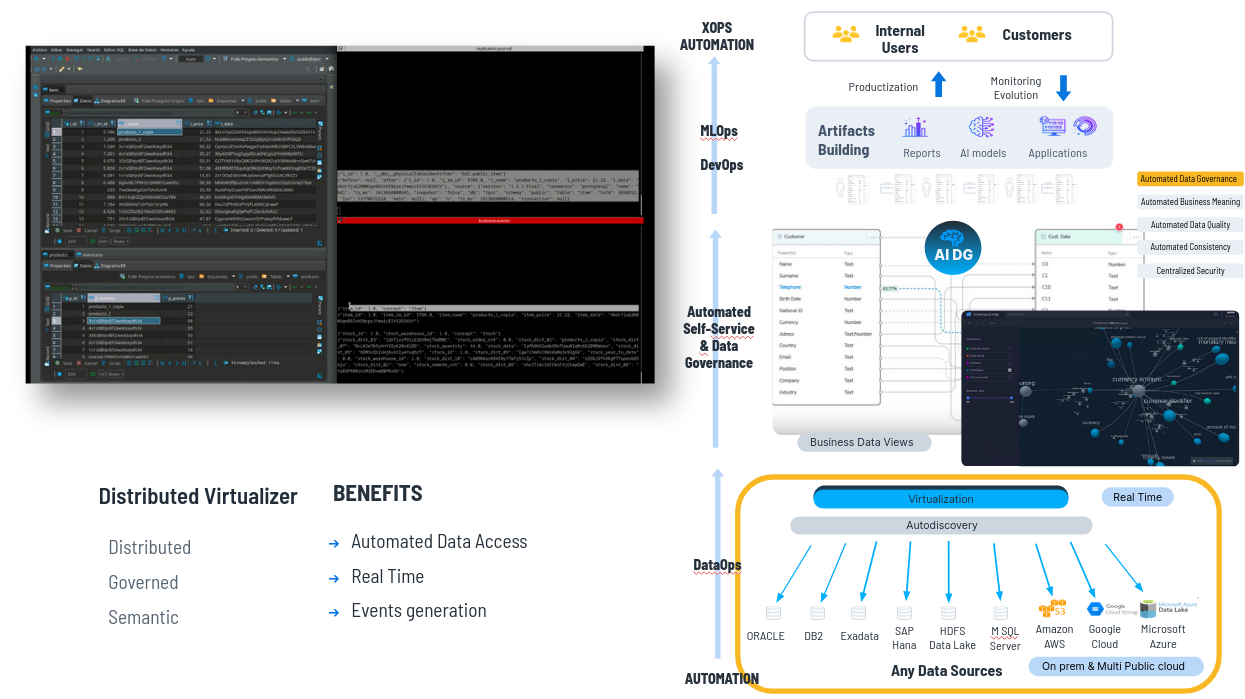
El virtualizador puede acceder al dato en origen sin copiarlo ni moverlo. Aunque si quiero hacer una réplica porque acceder al core bancario directamente no esté permitido por temas ralentizaria los procesos, hay posibilidad de hacer una replica desde el gobierno del dato automáticamente, con asignar un metadato, un atributo a esta base de datos o una tabla en la que ponemos por ejemplo “replication = true”, automáticamente el virtualizador hace una réplica, la mantiene sincronizada en "near real time" o "real time" y virtualiza la réplica, sin tener que hacer programas.
Entonces, no movemos datos físicamente, a no ser que sea requisito de cliente. Y si necesitamos moverlos lo hacemos con programas, lo hacemos automáticamente desde el gobierno del dato.
Esto es Data Fabric, lo hago automáticamente desde el gobierno del dato.
____________________________________________________________________________________________________________________________________________________________________
¿Qué automatizamos con esto?
En acceso a los datos, somos 4 veces más rápidos y con menos tiempo que haciendo programas y además disponemos del dato en real time, porque accedemos al dato en el origen o sincronizamos near real time.
Generamos los eventos de realtime que automatizan luego operaciones en la compañía.
Automatizamos el acceso al dato y el movimiento de los datos.
____________________________________________________________________________________________________________________________________________________________________
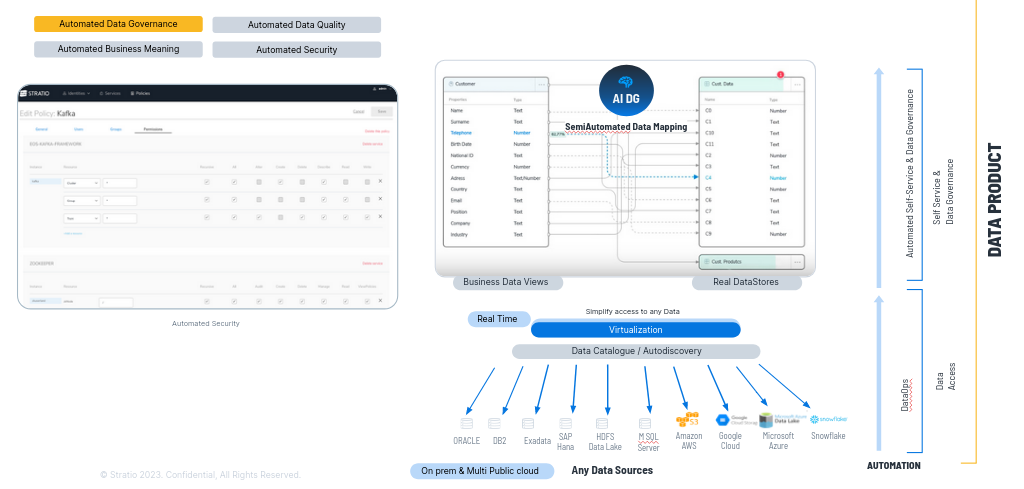
1.3. Suite de Gobierno del Dato
Normalmente el problema con el que nos encontramos es que estos esquemas se entienden mal por parte de usuarios no técnicos, por lo que en el segundo paso lo que hacemos será traducirlos a significado y términos de negocio.
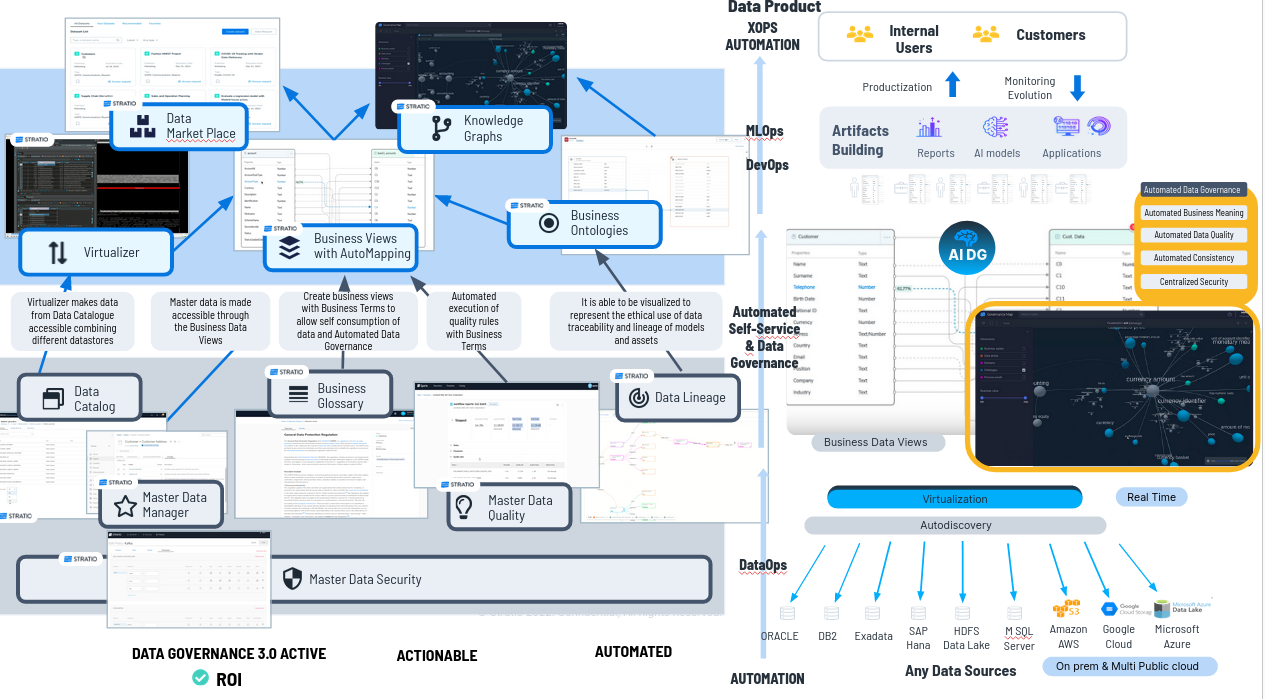
Creamos un
producto que se llama "Data Collections" que sea capaz de crear una vista
de negocio y creamos tantas "Business Views" como queramos, porque no consumen
practicamente recursos.
Estas Business Views contendrán términos de negocio que vienen desde el glosario de negocio (Business Glossary) o palabras que los usuarios de negocio entienden perfectamente,
siendo las que nuestros clientes usan en el día a día.
A continuación ayudamos a mapear semi automáticamente los términos de negocio, las propiedades de la business view, con los datos que están disponibles a través del virtualizador y una vez que los he mapeado, publico la vista de negocioy los usuarios pueden consumir los datos con las vistas de negocio.
Permitimos el autoconsumo del dato porque lo entienden perfectamente. Además al mapear hacemos gobierno del dato semi-automáticamente.
Ejemplo: Al mapear, en una tabla de un Oracle, una columna se llamaba C4 pero hemos identificado con algoritmia que en realidad es el teléfono, con lo que al mapearlo además de poder acceder a ese dato con teléfono en lugar de con C4 hacemos gobierno del dato automáticamente, automatizamos el gobierno del dato, podemos ejecutar la reglas de calidad de teléfono de C4 porque ahora sabemos lo que es.
___________________________________________________________________________________________________________________________________________________________
¿Qué estamos
haciendo?
Transformamos los datos en CONFIABLES, “trusted”, con calidad y con
seguridad . Así cuando utilizamos estas vistas, además de ontologías
propiamente formadas, somos capaces de aumentar los datos al
hacer el mapeo con esquemas de grafos o esquema semánticos con lo que
todos los casos de uso de clientes los mejoramos.
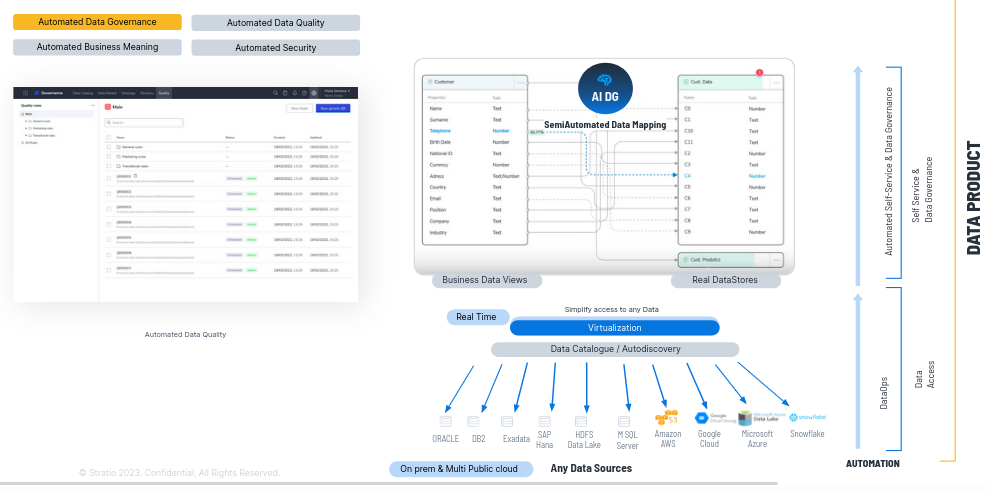
Permitimos el AUTOCONSUMO DEL DATO porque traducimos los datos técnicos a términos de negocio y TRANSFORMAMOS EL DATO EN CONFIABLE y lo AUMENTAMOS, justo lo que indican Forrester y Gartner que hay que hacer.
Cuando
además en estas vistas se utilizan ontologías somos capaces de crear
esquemas de grafos y semánticos para poder resolver problemas de mejor
manera.
___________________________________________________________________________________________________________________________________________________________
¿Cómo hacemos el movimiento a
Public Cloud?
Con las vistas de negocio nosotros somos capaces no solo
de mapear datos sino de crear nuevos datos. Se pueden utilizar fórmulas
matemáticas o scripts con SQL para combinar los datos que me llegan.
Luego esos datos si a esta business view se les añade un atributo,
por ejemplo: replication_destiny=aws.snowflake/microsofazure.gen2 u otro; y
automáticamente el virtualizador lo mueve donde queramos.
Estamos
haciendo un datalake en la nube con unos solos clicks, y además lo
hacemos desde gobierno del dato. Movemos desde la definición de negocio,
no técnicamente. Defino un KPI desde mi business glossary y con una
formula y se me genera el dato.
¡Tardamos días en lugar de meses o años en mover datos de un data lake a una public cloud!
___________________________________________________________________________________________________________________________________________________________
1.4. Importancia de gobernanar la capa de datos semánticamente
El gobierno del dato es nuestra primera recomendación. Hay que gobernar los datos de manera accionable y semántica.
¿Qué quiere decir gobernar los datos semánticamente o desde la capa de negocio?
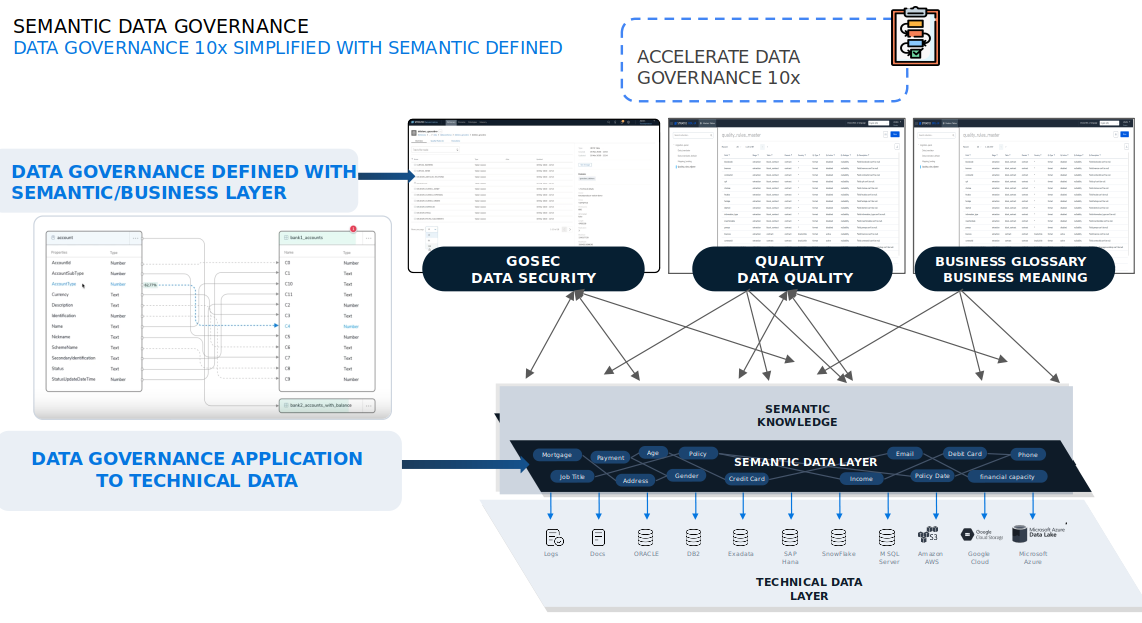
Para AUTOMATIZAR tanto gobierno del dato lo hacemos a partir del uso de la IA Generativa.
En nuestro producto, el gobierno del dato la IA generativa es el Core. Se generan términos de negocio, reglas de calidad, utilizando el lenguaje natural, de forma automática. Aceleramos el gobierno del dato x4.
Somos capaces de hacer en 3 meses lo que con una herramienta clásica de mercado se tardaría un año.
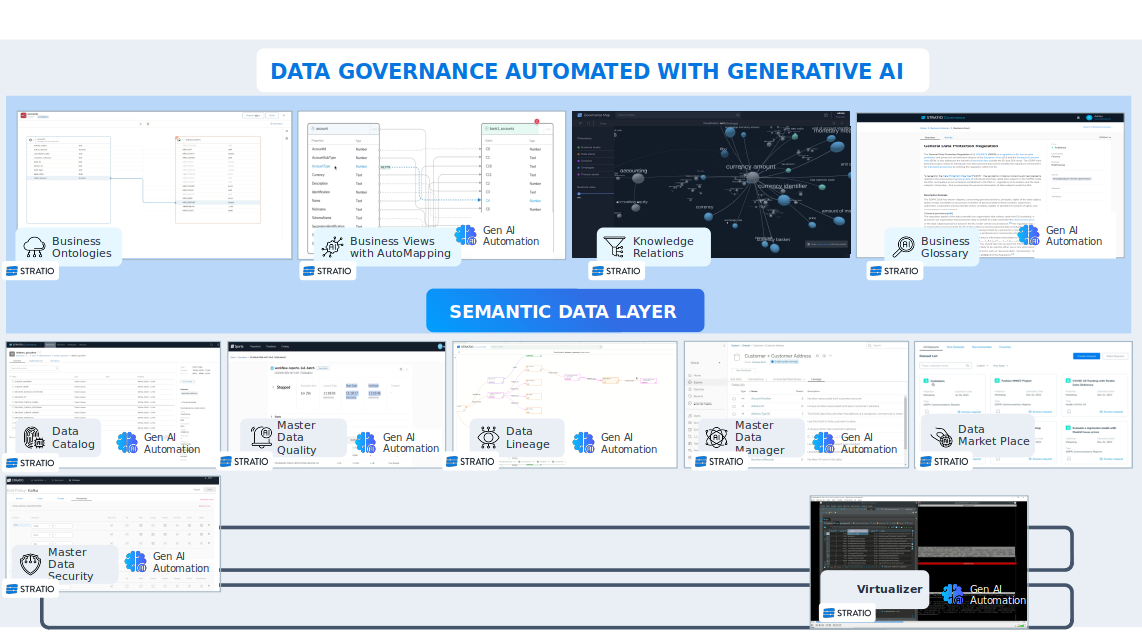
1.5. Suite Gobierno del dato e IA Generativa
¿Cómo aplica esto a la IA Generativa?
El código que genera GEN AI con esquemas técnicos NO FUNCIONA, generaría alucinaciones, porque entiende conceptos de negocio, no datos técnicos.
Traduce los esquemas técnicos a Business Views, términos de negocio que es lo único que entienden los motores de Gen AI. O traduces tus esquemas técnicos a vistas de negocio con conceptos de negocio o no puedes usar Gen AI. La business View es un Must-to–Have.
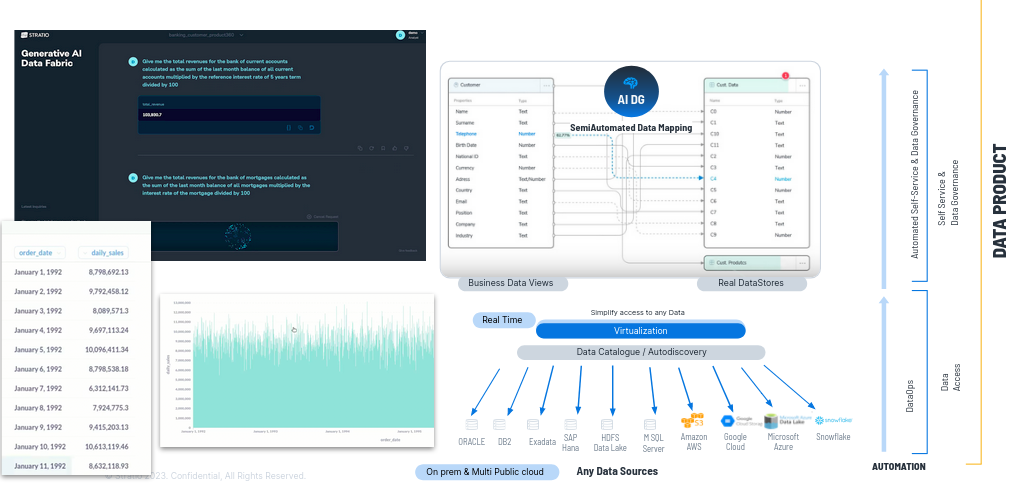
No solo podemos mapear datos, sino que podemos crear nuevos datos con fórmulas, cuyas fórmulas y scripts que los crean, los generamos con Gen AI. Con lo que generamos nuevos datos sin esfuerzo humano, 10 veces más rápido, reducimos el coste x 10 y habilitamos el uso de Gen AI.
Es la única manera de utilizar Gen AI en el concepto de los datos.
___________________________________________________________________________________________________________________________________________________________
1.6. Data Product Market Place
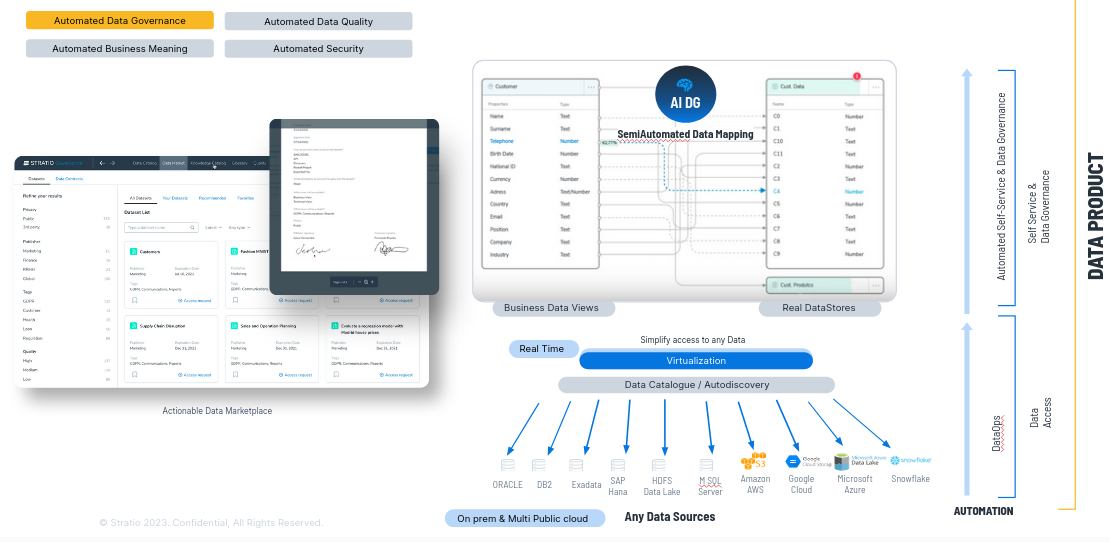
Cualquier Data Product que hace una compañía lo automatizamos con Gen AI y una vez que hemos creado el Data Product por un usuario de negocio describiéndolo funcionalmente, lo publicamos en un Data Product Market Place, con seguridad a través de la creación de smart contracts.
1.7. Suite de Analítica Avanzada
¿En general para qué se utilizan los datos en las empresas?
Principalmente hacemos reports, dashboards, workflows para generar KPIs o transformar los datos (80%), hacemos modelos de inteligencia artificial o aplicaciones inteligentes.
En la Suite de Analítica Avanzada con IA generativa,
aceleramos toda la transformación de datos, en lenguaje natural,
generando el código de forma automática, lo mismo a la hora de crear
modelos de machine learning. También el Core es la IAGenerativa.
En toda la suite de Gen IA hemos embebido inteligencia artificial generativa para generar los modelos mucho más rápido, automáticamente y productivizarlos de forma más eficaz.
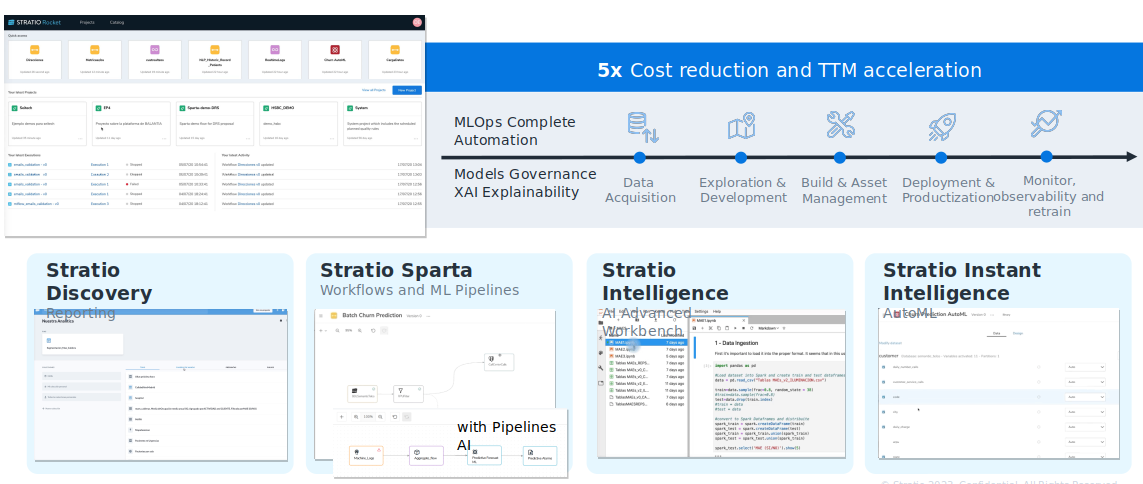
Stratio Rocket permite desarrollar workflows con herramientas zero code o low code, hacer reportes sencillos, generar nuevos KPIS, manejar datos de IOT, de M2M, Real Time, hacer modelos de Machine Learning, de Deep learning, de Tensorflow, de Spark, de redes neuronales pero automatizando toda la parte de MLOps, productivización de modelos, monitorización de artefactos, devolución automática y gobernando todos esos artefactos, con lo que en este último paso permitimos hacer un modelo en 1/5 del tiempo que se suele tardar.
2. Conclusiones sobre Data Fabric
________________________________________________________________________________________________________________________________________________________________
Realizamos una democratización de inteligencia artificial,
ponemos a disposición de las personas el uso del la inteligencia
artificial, sin necesidada de que estas tengan conocimientos profundos
de ciencia de datos.
Data Fabric reduce coste en las public cloud más o menos a la mitad. Porque levantamos y apagamos las cosas automáticamente.
Automatizamos y permitimos industrializar el uso de la inteligencia artificial.
3. Data Fabric con Stratio Generative AI Data Fabric
Podemos ver el concepto de Data Product (derecha) en correspondencia en las diferentes capas y herramientas del producto de Stratio Generative AI Data Fabric (izquierda).
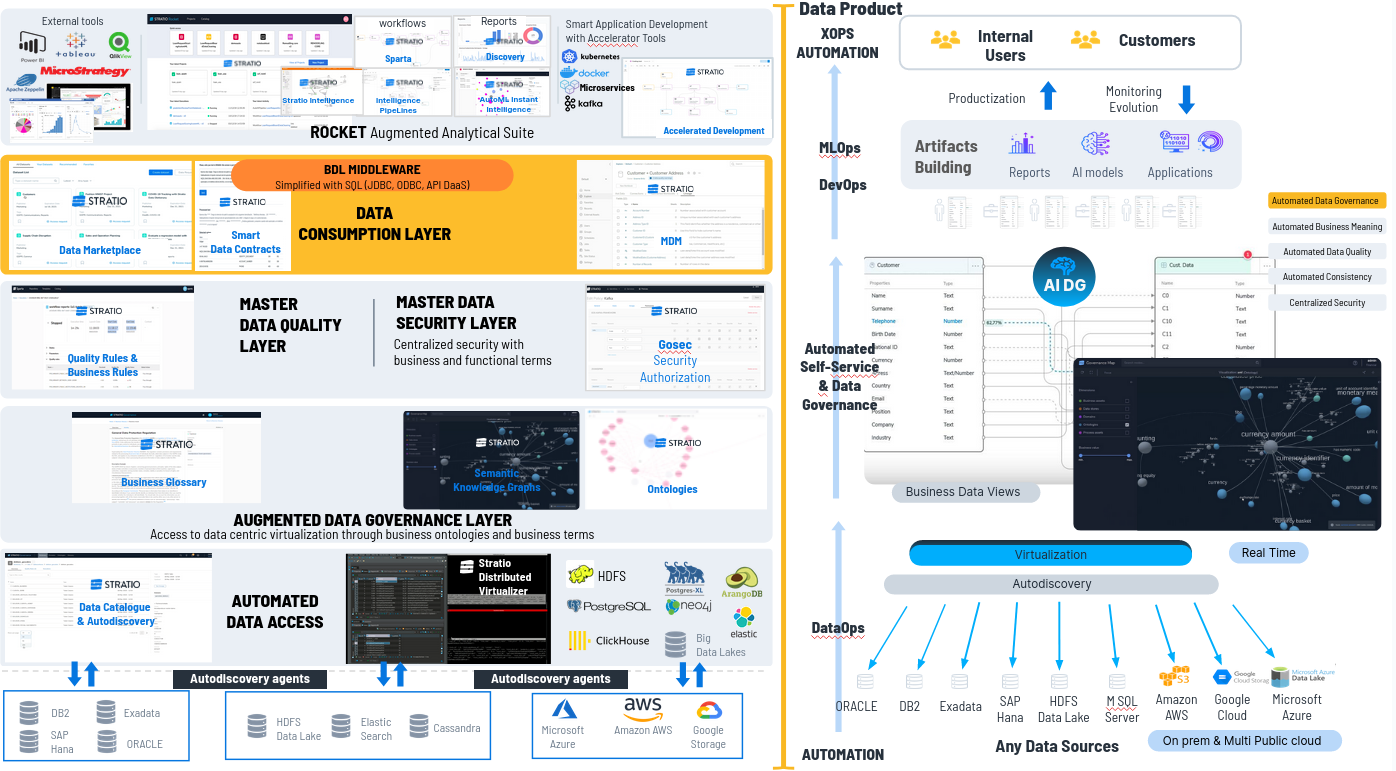
Todo esto se traduce en que en las primeras capas, tenemos las herramientas de gobierno del dato (Stratio Governance) y el virtualizador (Stratio Virtualizer) , con:
- Data catalogue para acceder, crear el catálogo de datos y crear metadatos enriqueciendo ese catálogo de datos
- Virtualizador para acceder al dato
- Business Glossary para definir business terms con data owner's y data steward etc. y poderlos utilizar para hacer Business Views y mapear los datos
- Aplicación para manejar ontologías y luego ver los datos con esos esquemas semánticos y de grafos.
- Data Quality Layer como aplicación de calidad para definir reglas de calidad y de negocio gráficamente. Esta aplicación genera código que luego lo que queda automáticamente nuestros productos casi todos son low code y cero code.
- Data Security Layer en la definimos reglas de seguridad que luego se aplican también automáticamente
- Master Data Manager. Este es un MDM que proporciona un valor inmediato muy rápido a cualquier cliente.
- Data Marketplace en el que puedo publicar colecciones de datos generados con el data fabric para que los usuarios los pueden auto consumir solicitando acceso y si se les da acceso a cualquier colección de datos se genera un datacontract en el que tienen responsabilidad de lo que hacen con esos datos y se audita y securiza todo lo que hacen con los datos en el data marketplace.
Y a continuación, la suite analítica avanzada (Stratio Rocket) para desarrollar todos estos artefactos automatizando MLOps y gobernandolos. esos artefactos o en la suite de desarrollo de aplicaciones inteligentes.
4. Data Fabric como Plataforma Distribuida
Stratio es un gestor de Kubernetes, un gestor de contenedores con Kubernetes y por lo tanto todas estas aplicaciones que hemos visto las desplegamos en contenedores.
Stratio Command Center es un Market Place disponible, con aplicaciones de Stratio y Tecnologías de código abierto disponibles con un solo clic.

El cliente puede decidir qué herramientas necesita en cualquier momento dando flexibilidad completa para implementar solo según necesidad.
¿Cuál es la ventaja?
Somos una plataforma distribuida. No tengo que utilizar todo el Data Fabric para aportar valor a un cliente.
__________________________________________________________________________________________________________________________________________________________
__________________________________________________________________________________________________________________________________________________________
Ejemplos:
Un cliente solo quiere el virtualizador: haciendo un clic se hace un deployment del virtualizador y solo ejecutan, usan y pagan el virtualizador, está todo desacoplado. Si quieren empezar con gobierno del dato, por ejemplo, solo con la parte de calidad, pues empieza solo con la parte de calidad de gobierno del dato.
Quiere hacer modelos de inteligencia artificial pues empieza solo con Rocket, está desacoplado. Pero además de incluir los productos de Virtualización de gobierno del dato y de analítica avanzada del Data Fabric, incluimos en nuestra plataforma de contenedores una serie de tecnologías open source que no son las Open Source. ¡Muy importante! Securizamos, es decir, resolvemos los bugs de seguridad que tiene, resolvemos los bugs y damos soporte 24/7 de todas estas tecnologías Open Source.
Que quiero hacer redes neuronales pues en el Command Center con un clic despliegas una red con Tensor Flow, un cluster.
Que quiero ejecutar Machine Learning o workflows en real time, con un clic despliego un cluster de Spark.
Que quiero hacer una base de datos de grafos, con un clic despliego Arango.
Que quiero hacer un sistema de búsqueda, con un clic despliego Elastic. Es decir, incluimos las tecnologías Open Source en el estado del arte en la innovación de data, disponible en el mercado pero hecho Enterprise Ready, con lo que entre estas 3 tecnologías open source y los productos de data fabric somos capaces de resolver cualquier caso de uso, pero con el nuevo concepto de data fabric es decir automatizando las cosas y desde el gobierno del dato.
5. Data Fabric como Plataforma Inclusiva
A su vez en esta parte de ser INCLUSIVOS, no tenemos que reemplazar herramientas. Importamos lo que han hecho y les ponemos en valor.
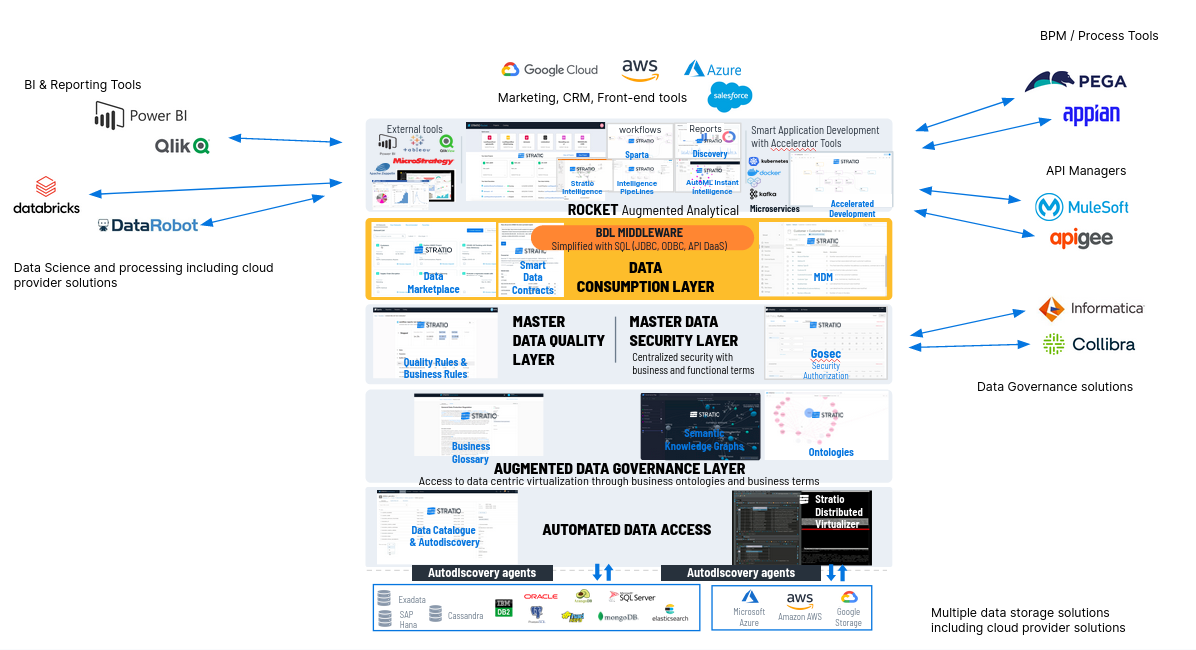
Ejemplos:
- Si un cliente está utilizando algo de gobierno del dato, Informática o Collibra, por ejemplo, estamos integrados con esos productos. Importamos lo que han hecho y lo ponemos en valor.
- Si un cliente quiere usar DataRobots o Databriks, no pasa nada, utilizas el gobierno del dato y el virtualizador y no tienes por qué utilizar Stratio Rocket, está desacoplado y nos integramos con diferentes sistemas.